一、背景篇:为什么你需要一款“傻瓜式”爬虫工具?
在大数据时代,数据就是黄金!但很多小伙伴一听到“爬虫”就头大:
👉 程序员:写代码调试到凌晨3点,反爬机制让人头秃;
👉 非技术党:想抓点数据做分析,但Python都还没学会;
👉 企业用户:担心数据隐私,怕被第三方平台“偷家”……
这时候,EasySpider横空出世了!
这款工具号称“爬虫界的外卖软件”——不用自己做饭(写代码),点一点就能吃到数据大餐!更重要的是,它完全开源免费,数据全程本地保存,连广告都没有!
(别急,后面有手把手教程!先看它的逆天功能👇)
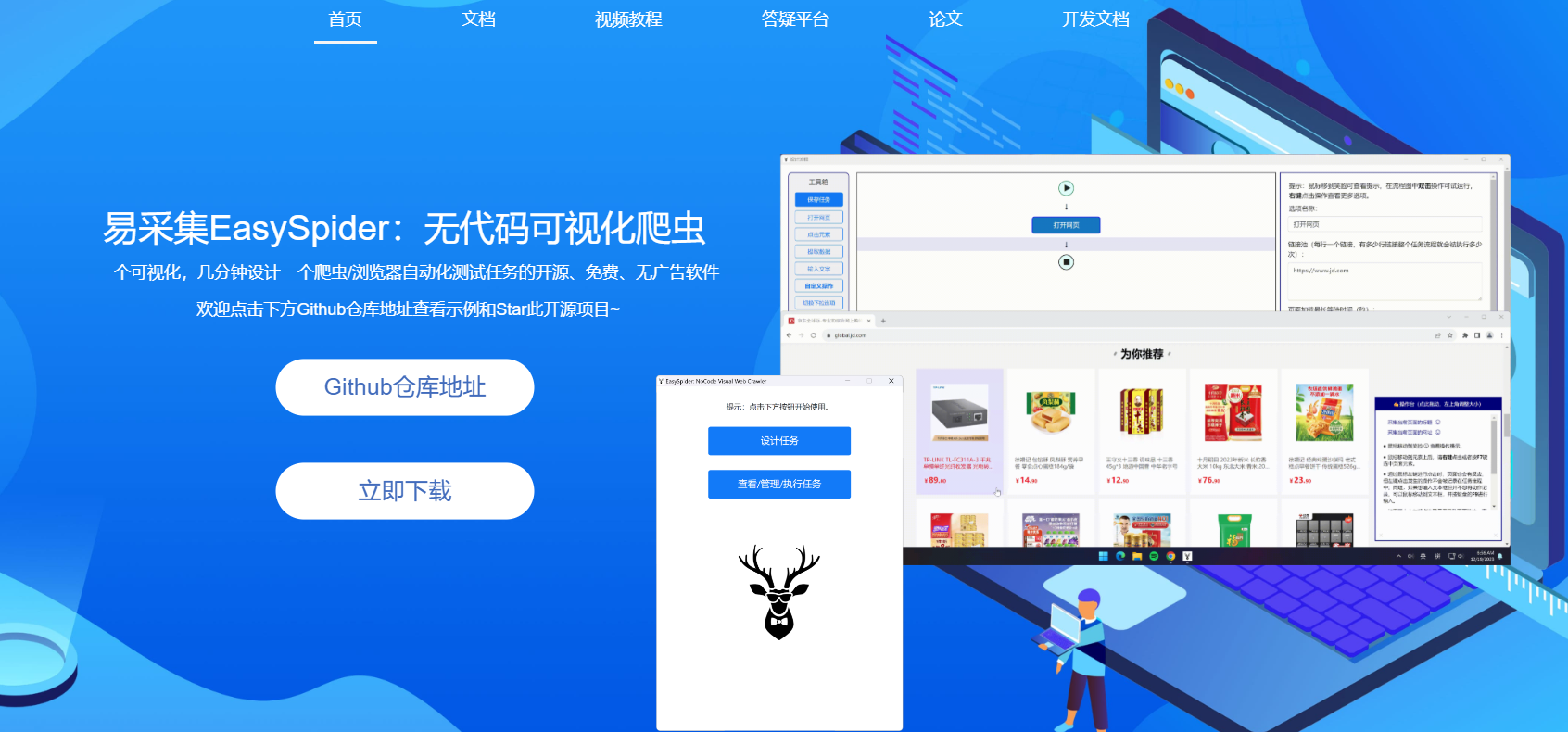
二、工具介绍篇:EasySpider到底强在哪?
1. 零代码操作,小学生也能玩转
想象一下,用Excel表格的拖拽操作就能设计爬虫任务是什么体验?
EasySpider的可视化界面让这一切成真!选中网页元素→设置采集规则→点击运行,三步搞定!
举个栗子🌰:想抓淘宝“猜你喜欢”的商品信息?只需在商品卡片上右键选中,软件自动识别同类元素,一键采集名称、价格、链接!全程不用写一行代码。
2. 功能强大到离谱
你以为它只是个基础工具?Too young!
- 动态内容支持:连JavaScript生成的页面也能抓取(比如评论区瀑布流);
- OCR识别:截图网页文字直接转成文本,连图片里的信息都不放过;
- 定时任务:设置凌晨自动抓取,睡醒就能看到新鲜数据;
- 命令行执行:高手还能嵌入到其他系统里玩自动化。
3. 安全又省心
- 数据本地存储:所有任务和结果都保存在你的电脑上,绝不经过第三方服务器;
- 跨平台支持:Windows、Mac、Linux全都能用,甚至还能在手机模式抓移动端页面;
- 开源透明:GitHub上21.7K星标项目,代码随便查,绝对无后门。
三、教程篇:3分钟上手,小白秒变爬虫高手!
第一步:下载安装
- 访问官网 https://www.easyspider.net 或GitHub Releases页面,选择对应系统的安装包;
- 解压后无需复杂配置,双击即可运行(绿色版连安装都省了!)。
第二步:设计任务(以抓取豆瓣电影TOP250为例)
- 创建新任务:打开软件→选择“纯净版浏览器设计”→输入豆瓣电影TOP250的网址;
- 选中元素:鼠标悬停在电影名称上,右键选择“扩大选区”,软件会自动识别所有电影条目;
- 设置字段:在右下角操作台中,勾选“电影名称”“评分”“导演”等字段;
- 保存任务:点击左侧“保存任务”,命名为“豆瓣电影采集”。
第三步:运行与导出
- 一键运行:点击“本地直接执行”,数据自动开始抓取;
- 查看结果:在软件目录的Data文件夹中找到CSV文件,用Excel打开即可分析;
- 进阶玩法:
- 设置定时任务:每天自动更新数据;
- 调用OCR:识别电影海报中的文字;
- 命令行集成:结合Python脚本做深度分析。
四、避坑指南:这些细节要注意!
❗️常见问题
- 动态加载失败:部分网站需要滚动页面加载内容,记得在流程中添加“滚动页面”操作;
- 验证码拦截:遇到验证码时可手动处理,或通过IP代理池规避(企业级需求建议搭配专业反反爬工具);
- 数据错位:确保字段选择准确,可用“预览数据”功能实时校验。
💡高阶技巧
- 循环与条件判断:比如“点击‘下一页’直到结束”,用无限循环+终止条件轻松实现;
- 调用外部程序:抓取完成后自动调用Python脚本清洗数据;
- 云服务器管理:团队协作时可配置统一任务库。
五、结语:数据自由,从此开始!
EasySpider的出现,彻底打破了爬虫的技术壁垒。无论你是想抓竞品价格、监控舆情,还是做学术研究,它都能成为你的“数字助手”。更重要的是,开源社区的力量让这款工具持续进化——GitHub上每天都有新功能提交,遇到问题还能直接向开发者提问!
最后送上金句:
“不会编程?没关系!EasySpider让你用‘点点点’征服数据江湖!”
立即行动:
👉 GitHub地址:https://github.com/NaiboWang/EasySpider
👉 官网下载:https://www.easyspider.net
P.S. 如果这篇文章让你少掉了10根头发,记得点赞收藏!(数据证明,每转发一次,拯救一名程序员的发际线!)💻✨
# EasySpider # 爬虫 # 开源