OpenAI正式发布了GPT-4.1系列模型,该系列包含GPT-4.1、GPT-4.1 mini和GPT-4.1 nano三个模型,均通过API调用,已向所有开发者开放。这些模型在关键功能上提供了类似或更强的性能,同时成本和延迟更低,因此OpenAI将在三个月后(2025年7月14日)弃用GPT-4.5预览版。
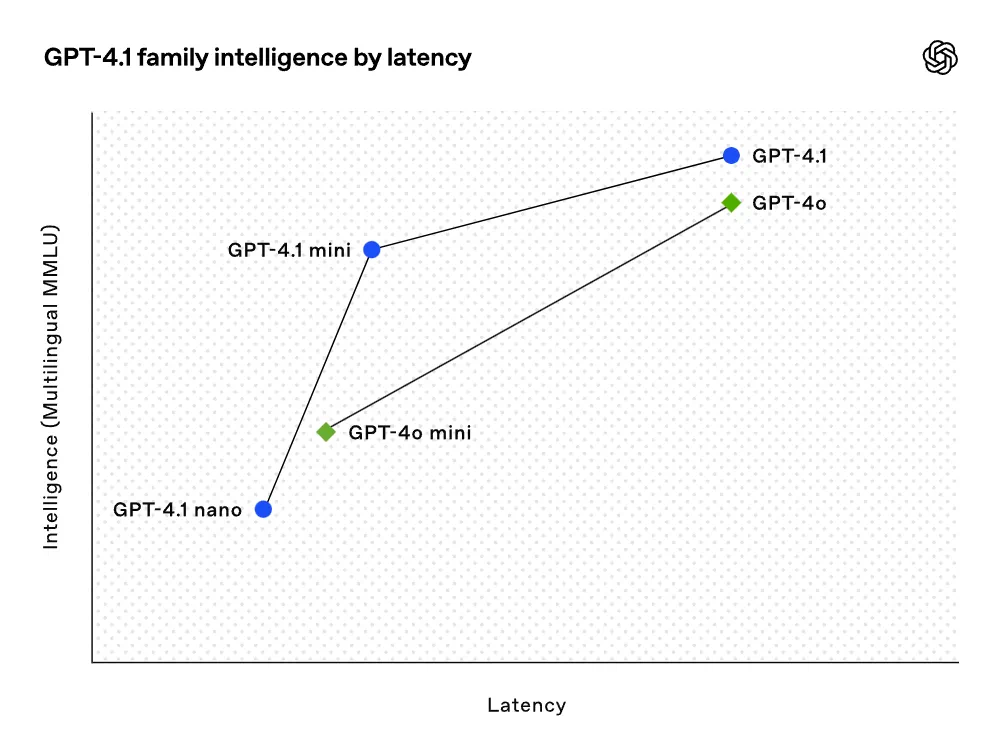
性能提升
编程能力
- SWE-bench Verified测试:GPT-4.1得分为54.6%,比GPT-4o提升21.4%,比GPT-4.5提升26.6%。
- Aider多语言差异基准测试:GPT-4.1的得分是GPT-4o的两倍多,甚至比GPT-4.5高出8%。
- 前端编程:GPT-4.1在创建功能强大且美观的Web应用方面显著优于GPT-4o,人工评分结果显示其网站更受欢迎。
指令遵循
- Scale MultiChallenge基准测试:GPT-4.1得分为38.3%,比GPT-4o提升10.5%。
- 内部指令遵循评估系统:GPT-4.1在困难提示方面的表现优于GPT-4o,尤其在多轮指令遵循方面表现更佳。
长上下文理解
- Video-MME基准测试:GPT-4.1在长篇无字幕测试中得分为72.0%,比GPT-4o提升6.7%。
- OpenAI-MRCR评估:GPT-4.1在处理上下文长度高达100万个token时表现优异,能够准确提取与任务相关的信息。
视觉理解
- 图像基准测试:GPT-4.1 mini在多个图像基准测试中表现优于GPT-4o。
- Video-MME多模态长上下文理解:GPT-4.1得分为72.0%,高于GPT-4o的65.3%。
模型特点
GPT-4.1
- 全面超越GPT-4o:在编程、指令遵循和长上下文理解等方面均有显著提升。
- 支持100万个上下文token:能够处理更长的上下文,适合处理大型代码库或长文档。
GPT-4.1 mini
- 小型模型性能飞跃:在多项基准测试中超越GPT-4o,延迟降低近一半,成本降低83%。
- 适合多种任务:在智能评估、编程和多语言编码任务中表现优异。
GPT-4.1 nano
- 速度最快、成本最低:适合低延迟任务,如分类或自动补全。
- 性能卓越:在MMLU测试中得分为80.1%,在GPQA测试中得分为50.3%,高于GPT-4o mini。
实际效用与优化
GPT-4.1系列模型不仅在基准测试中表现出色,还注重实际效用。OpenAI与开发者社区密切合作,针对开发者应用最相关的任务优化了这些模型。以下是具体优化方向:
编程任务
- 代码diff格式:更可靠地遵循diff格式,减少无关编辑。
- 输出token限制:GPT-4.1的输出token限制增加到32,768个,高于GPT-4o的16,384个。
指令遵循
- 格式遵循:提供自定义格式的指令,如XML、YAML等。
- 负面指令:避免特定行为,如「不要要求用户联系支持人员」。
- 有序指令:按顺序执行多条指令。
- 内容要求:输出包含特定信息的内容。
- 排序:按特定方式对输出进行排序。
- 过度自信:在信息不可用时回答「我不知道」。
长上下文处理
- 多轮共指:能够识别并消除上下文中隐藏的多个「needle」。
- Graphwalks评估:在多跳长上下文推理中表现优异。
价格与成本优化
GPT-4.1系列模型在成本和延迟方面实现了显著优化:
- 中等规模查询成本:比GPT-4o低26%。
- GPT-4.1 nano:OpenAI迄今为止最便宜、速度最快的模型。
- 即时缓存折扣:从50%提升至75%,适用于重复传递相同上下文的查询。
- 长上下文请求:无需额外付费。
总结
GPT-4.1系列模型在性能、成本和实际效用方面都取得了显著进步,为开发者提供了更强大的工具。OpenAI的这一发布无疑将推动AI技术在各个领域的进一步应用和发展。
# openai # chatgpt # gpt